

Auralis for Customer Support Teams
Deflection that compounds. AHT and FRT that move. CSAT that holds. Built for support leaders who measure outcomes, not activity.
AI for customer support teams. Deflection that compounds. AHT and FRT that move. CSAT that holds. Built for support leaders who measure outcomes, not activity.
Why AI for customer support teams matters
Customer support leaders measure four numbers: deflection rate, average handle time (AHT), first response time (FRT), and CSAT. The renewal conversation in Q4 grades on those four, not on the AI feature list in the vendor's deck.
Most AI-for-support deployments still struggle to move all four. The published 2026 data is consistent: median deflection stalls at 41%, AHT and FRT improvements vary widely by deployment maturity, and CSAT on AI-handled tickets sits 0.2 points below human-agent CSAT (Zendesk CX Trends 2026).
Auralis is built for the customer-support-leader role: outcome-contracted, vendor-owned optimization, weeks to first measurable value. This page is the operating-model view: how it fits, what it ships, what is in the contract.
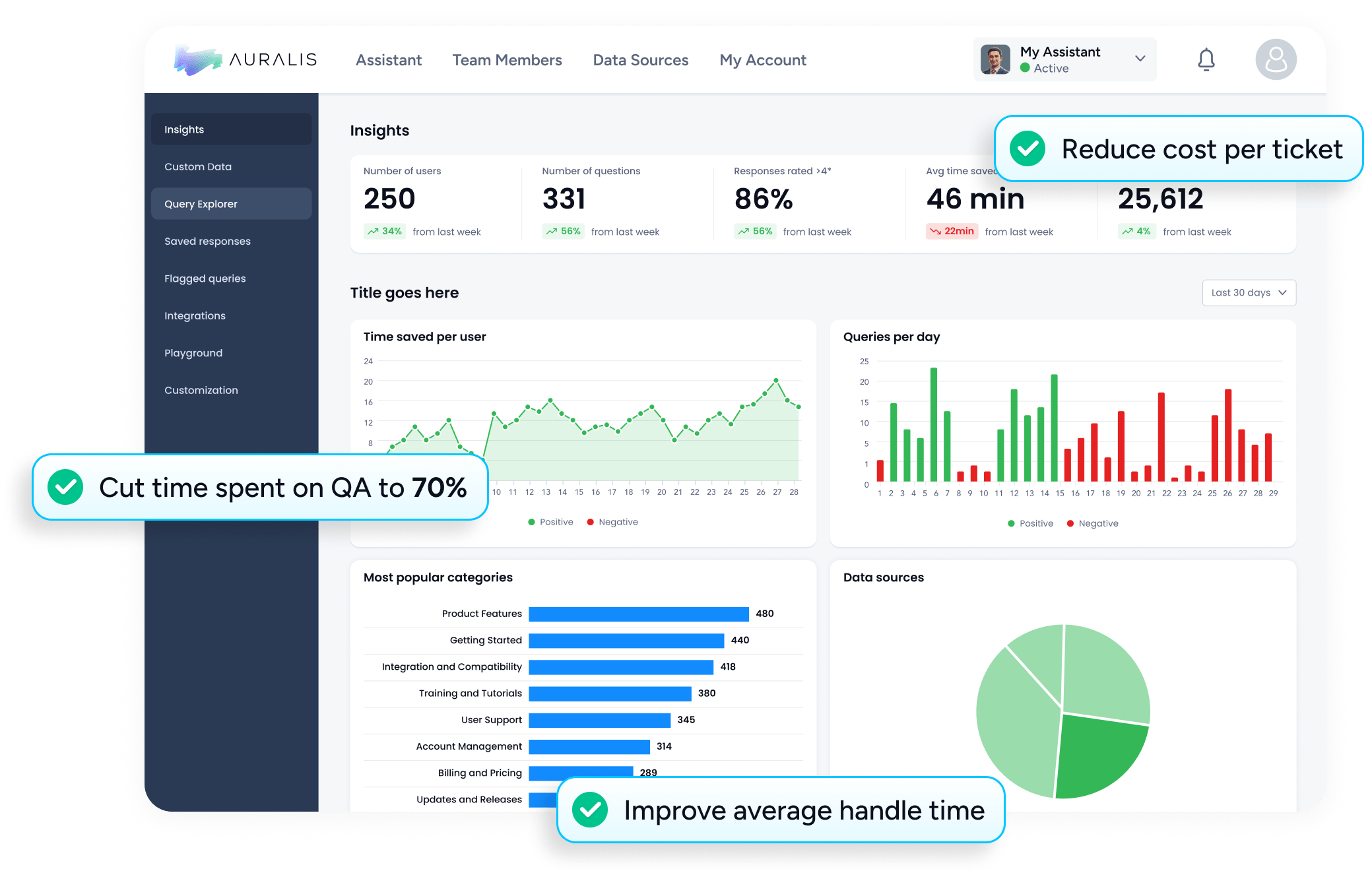
What we contract on
The Auralis SOW specifies outcome metrics, not feature access. Across the customer cohort:
- Deflection: ~60% in repetitive-question categories, steady-state.
- AHT: ~30% lower, blended across channels.
- FRT: ~35% faster (range 30-40%).
- CSAT: ~10 point lift, blended.
- Hours saved per agent / week: ~15 hours.
- Cost savings: up to ~30%.
These six numbers are audited weekly against the customer cohort export. The contract guarantees the model and the operating cadence; the cohort proves the result.
Who runs the optimization labor
The 95% generative-AI pilot failure rate documented by MIT in August 2025 traces consistently to a single pattern: optimization labor that sits with the customer's CX team in whatever bandwidth is available, not with a vendor-owned operating cadence.
Auralis closes that gap by ownership: the Auralis team runs the weekly KB-gap closure, threshold tuning, category-level recovery analysis, and confidence calibration. The customer's CX team reviews direction and signs off on changes; they do not author the operating loop.
The math compounds. A point of deflection gained in month two stays in the deployment in month twelve because the optimization loop never stops running. The Zendesk plateau curve at ~41% median flattens; the Auralis cohort curve continues.
The table below pairs the outcome metric on the contract with the published native-helpdesk-AI benchmark from the Zendesk CX Trends and Intercom Fin reporting.
What lands on the contract, what shows up in the dashboard
The six outcome metrics, audited weekly against the customer cohort.
| Metric | Native helpdesk AI (published) | Auralis steady state |
|---|---|---|
| Deflection (repetitive categories) | Zendesk median 41.2% / top quartile 58.7% | ~60% |
| AHT (blended) | Not consistently published | ~30% lower |
| FRT | Not consistently published | ~35% faster (range 30-40%) |
| CSAT | AI-handled 4.10/5 vs human 4.30/5 (Zendesk) | ~10 pt lift blended |
| Hours saved per agent / week | Not consistently published | ~15 hrs |
| Cost savings | Not consistently published | up to ~30% |
The Zendesk 41% median is the benchmark the rest of the category quietly accepts. Auralis lands ~20 points above as a baseline because the optimization labor is contracted, not aspirational.
How it lands across the stack
Auralis runs against whatever ticketing platform the customer support team already uses: Zendesk, Intercom, Freshdesk, Salesforce Service Cloud, custom helpdesks, hybrid combinations. The five Auralis modules map onto the support workflow:
- Autopilot: auto-resolve across email, chat, ticket queues.
- Assist: agent copilot for drafted replies, policy citations, next-best action.
- Audit: quality and recoverability scoring on every closed conversation.
- Answer: customer-facing chat surface with confidence-based escalation.
- Knowledge Center: the system of record for KB articles and the closed-loop drafting layer.
The five modules are one engagement, not five line items. The optimization cadence spans them; the Audit signal feeds the tuning across modules.
The four questions to ask any vendor
Use these on the next vendor call. They reveal the structure of the deal, not just the feature set.
Question 1. Which of the six outcome metrics will be in our contract? If the answer is “none” or “deflection only,” you're buying activity. The Auralis contract carries all six.
Question 2. Who owns weekly KB-gap closure? Vendor-owned with an SLA, or customer-owned in available bandwidth? The cadence answer determines the compounding curve.
Question 3. What is our time-to-first-value horizon? If the answer is “next quarter,” the build-path vendors don't fit. Days-to-weeks is the service-path signature.
Question 4. Can we measure recoverability, not just accuracy? The Audit signal instruments recoverability across the deployment. If your current vendor cannot describe its recoverability loop, the production tail is your problem.
For customer support teams, the choice between AI vendors isn't a feature comparison, it's an operating-model comparison. Auralis is built for the leaders who grade their quarter on the outcomes, contract for them, and want the vendor on the hook for the operating cadence.
The conversation starts with the four questions above and lands in the SOW with the six outcome metrics.
- Auralis Knowledge Center — where the KB-gap closure loop actually runs
Outcome numbers cited from published vendor research and the Auralis customer cohort. The contract structure reflects the standard Auralis SOW; specific terms vary by deployment scope and are discussed in evaluation.