

Improve Customer Experiences
Explore our resources and learn how to improve customer experiences at scale with AI and automation.

Retail POS Documentation and Unification
Retail POS at the Edge: What Runs the Store, What Slows It The operating reality Retail runs at the lane.

The Hidden Cost of ERP Nobody Talks About
The ERP budget you present to leadership covers implementation, licensing, and hardware. What it doesn't cover are the hidden costs that quietly drain your team and your margins long after go-live.

AI-Powered ERP Support: How to Automate 74% of Your D365 Help Desk
AI-powered ERP support automation can resolve 60-74% of support requests without human intervention by deploying intelligent agents that understand your D365 configuration, data, and business processes.
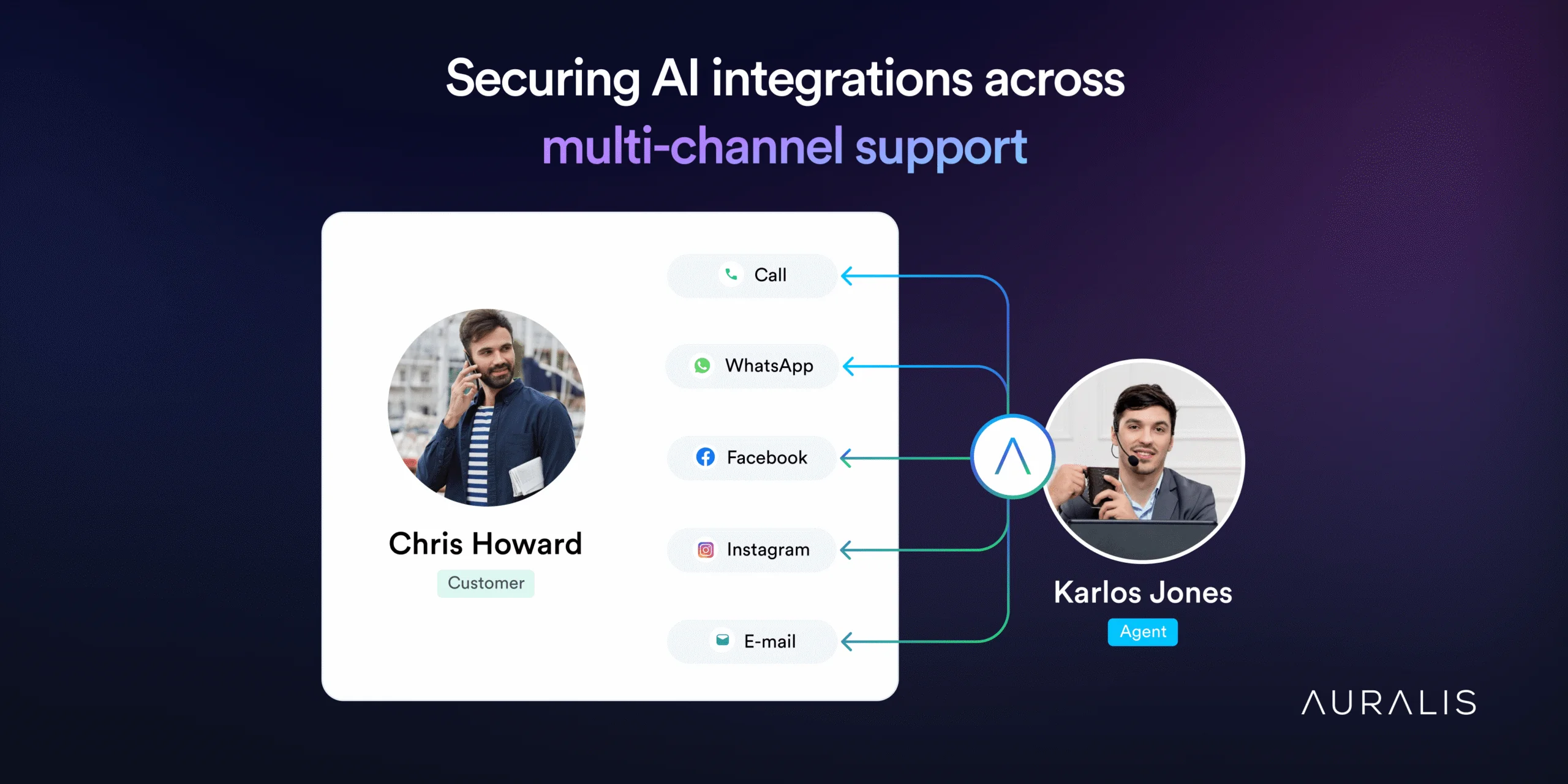
Securing AI Integrations Across Multi-Channel Support
Explore how to secure AI integrations in multi-channel support, protecting customer interactions across platforms.
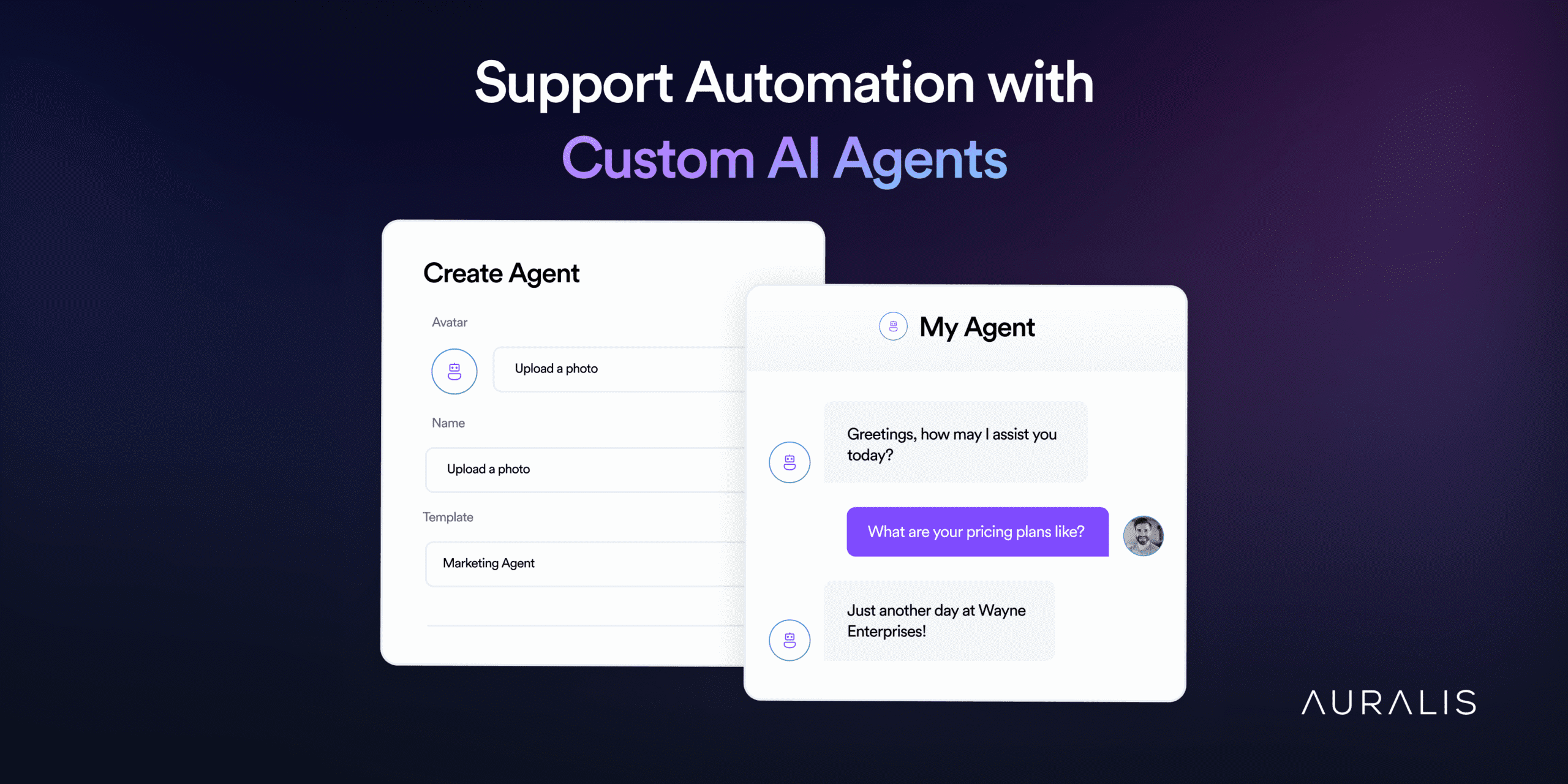
The Future of Customer Support Automation with Custom AI Agents
Explore future trends in AI-driven customer support automation, staying ahead with emerging technologies and innovative service strategies.
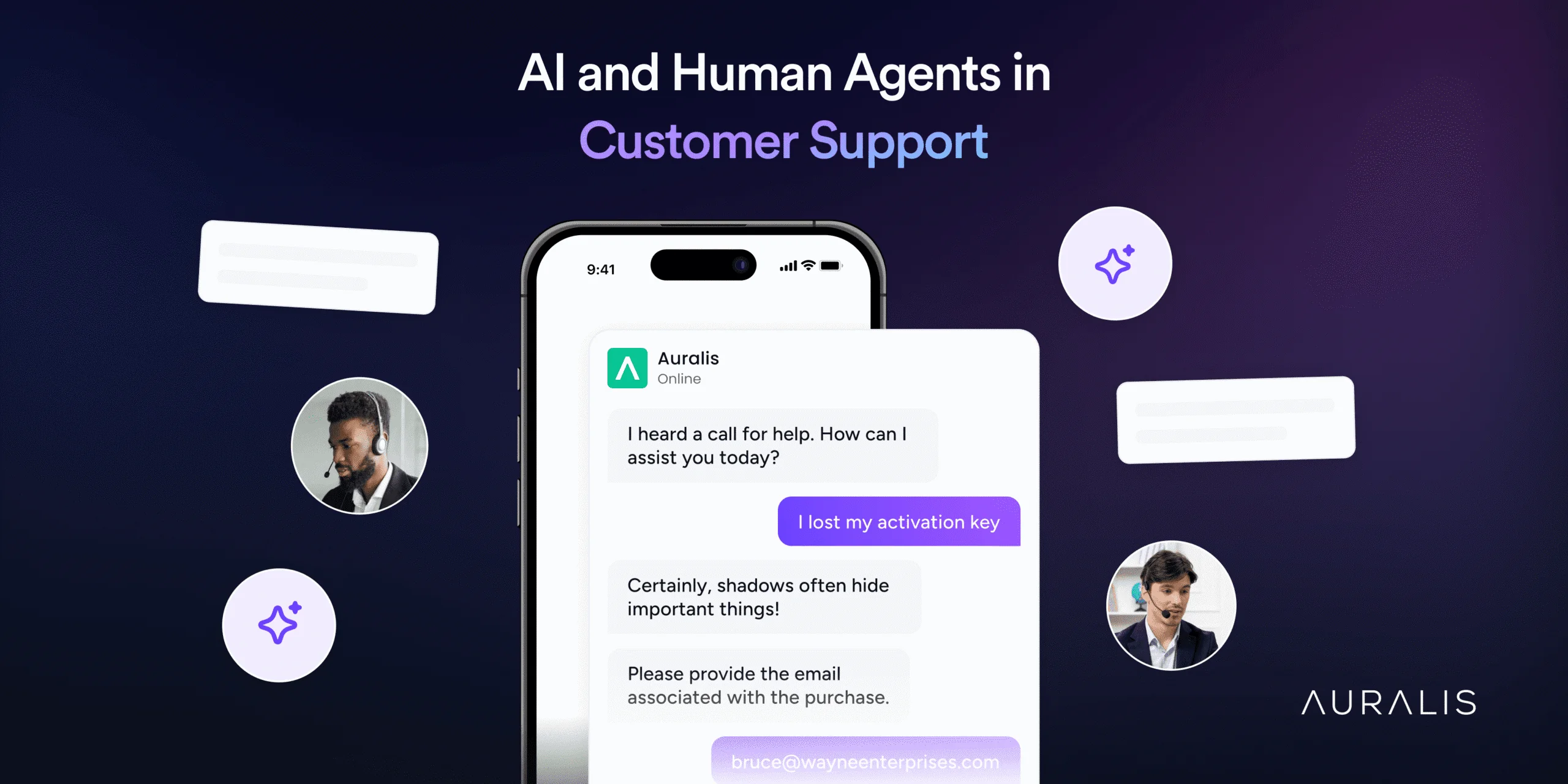
The Perfect Balance: How to Balance AI and Human Agents for Optimal Customer Support
Explore best practices to balance AI and human agents, achieving optimal customer service through smart collaboration.

How AI Co-Pilots Enhance Customer Support Efficiency
Learn how AI co-pilots enhance support efficiency, boosting productivity and customer satisfaction with smarter automation.

How to Navigate GDPR Compliance When Using AI for Customer Support
See how to achieve GDPR compliance with AI-powered support, ensuring data privacy and legal adherence in customer interactions.

Why and How to Integrate Your CRM System and AI Chatbots
Learn to integrate AI-powered chatbots with your CRM integration, streamlining customer management and enhancing data-driven decisions.
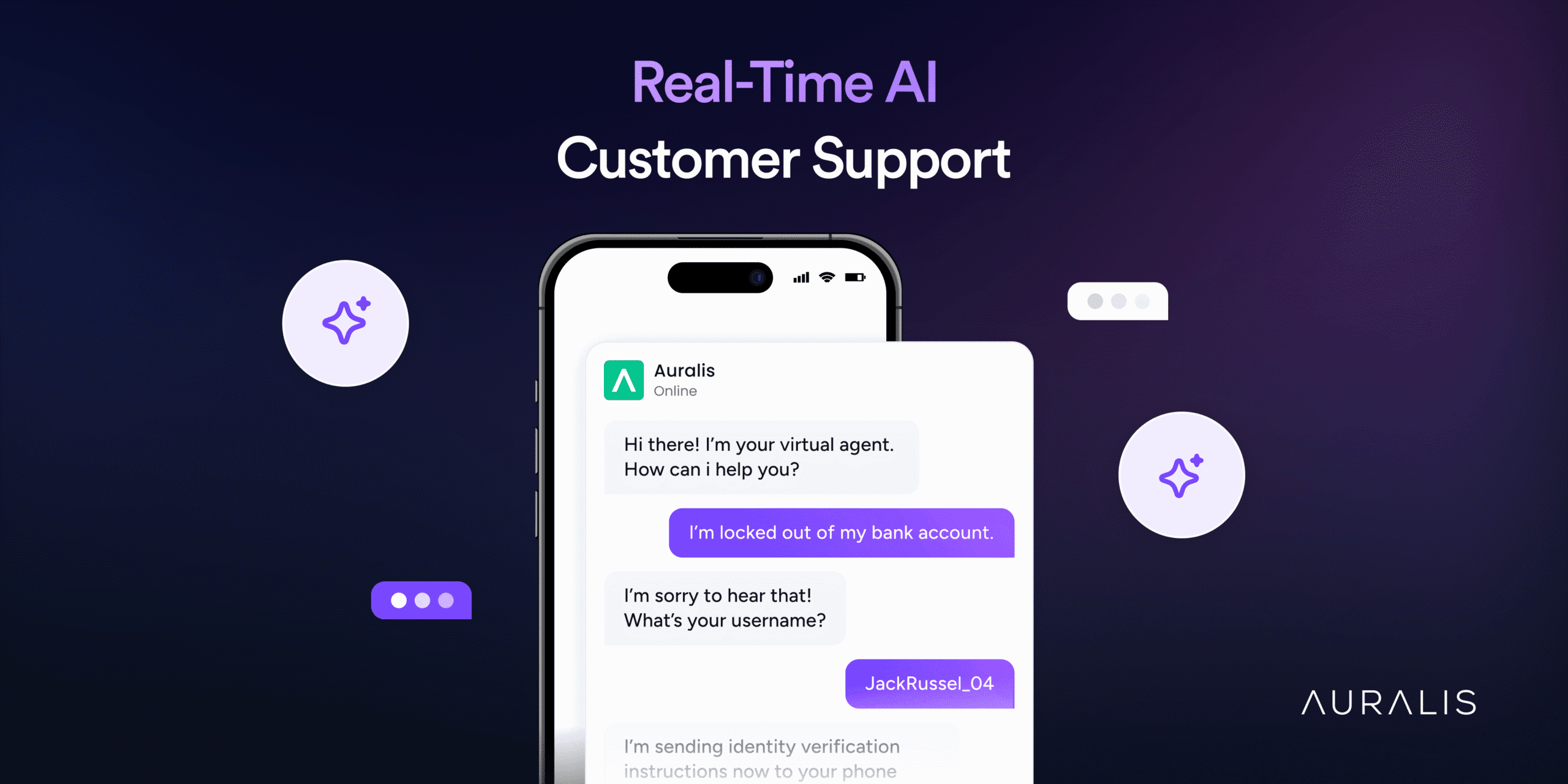
Real-Time AI Assistance: Revolutionizing Customer Support Today
See how real-time AI assistance transforms customer support by delivering faster and accurate service to queries.